
Kennenlernen der Webapplikation
Die Reconnaissance für den LUPFER hast du zwar bereits abgeschlossen, aber da du nun die Webapplikation genau untersuchen wirst, macht es Sinn, dass du sie erst einmal kennenlernst.
Rufe die Webseite auf, probiere sie aus und finde heraus, welche Funktionalitäten sie bietet.
Nun kannst du noch nach weiteren weniger offensichtlichen Informationen suchen. Mögliche Quellen dafür sind:
- Quellcode (HTML, JavaScript, CSS)
- HTTP-Header
- Directory-Bruteforcing
Wie du diese Informationen einsehen kannst, erfährst du in den folgenden Abschnitten.
Untersuchen von Quellcode
Die Development-Tools
Du kannst auf den clientseitigen Code, hauptsächlich HTML, CSS und Javascript zugreifen, weil dieser von deinem Browser ausgeführt werden muss. Dafür stehen dir die sogenannten Entwicklungstools deines Browsers zur Verfügung. Es gibt zwei Möglichkeiten, um die Entwicklungstools in Firefox zu starten:
- Drücken der
F12-Taste - Drücken der Tastenkombination
Strg+Shift+i
Damit öffnet sich ein Fenster. Es kann über das Menü an verschiedenen Stellen angefügt werden:
Untersuchen des HTML-Dokuments
In der Regel wird zunächst der Tab Inspektor geöffnet.
Dieser zeigt das HTML zur Laufzeit bzw. eine vereinfachte Version des Document Object Models (DOM) an.
Über den Node Picker kannst auf der Webseite einen Knoten auswählen. Er wird dann im Inspektor in Blau hervorgehoben:
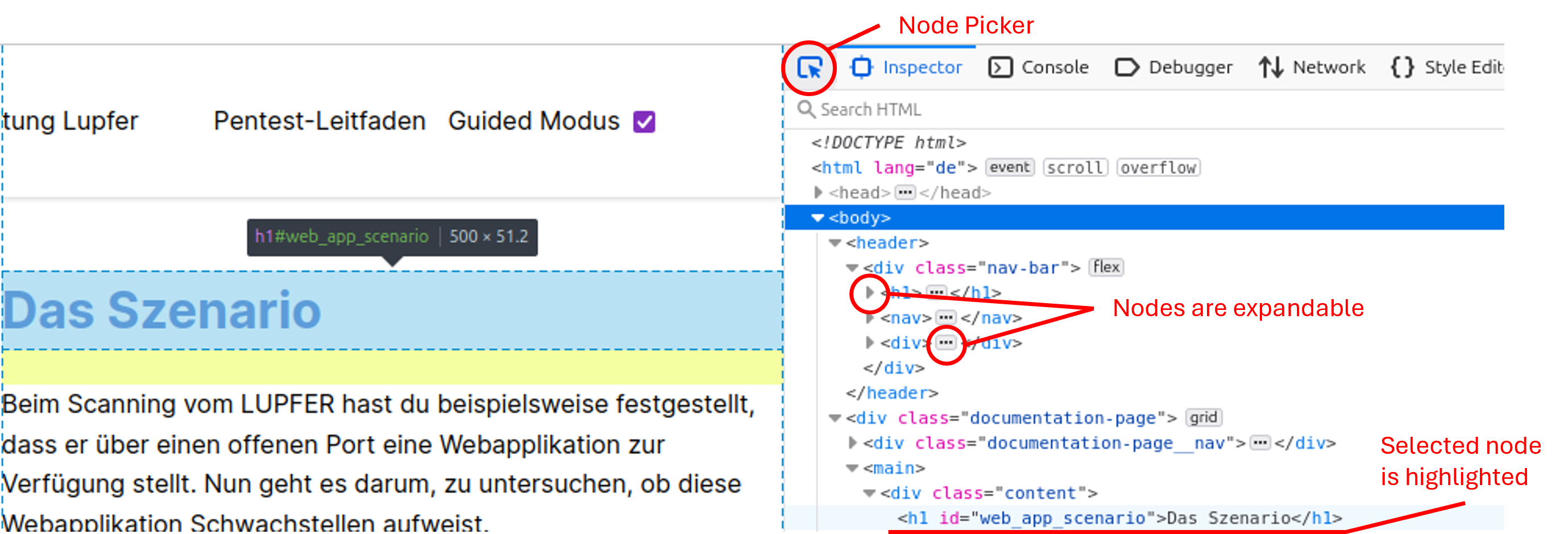
Um das DOM übersichtlich zu halten, sind die Knoten in der Regel zusammengeklappt. Um weitere Unterknoten oder Details zu erhalten, muss man entweder das Dreieck neben dem HTML-Tag oder die drei Punkte zwischen den Tags anklicken. Das DOM kann im Inspektor temporär manipuliert werden.
Bei der Reconnaissance solltest du gezielt nach Ressourcen gucken, die entweder im head-Bereich oder vor dem abschließenden </body>-Tag eingebunden werden.
Es kann sich um lokale Ressourcen handeln, die direkt auf dem Server der Webapplikation gespeichert sind, oder um externe Ressourcen von Drittanbietern.
Du siehst, dass die Webseite externe Ressourcen lädt:
Popper.js: Dies ist eine Bibliothek, um Elemente auf einer Weboberfläche zu positionieren.jQuery: Dies ist eine Bibliothek, die das Handhaben von Ereignissen vereinfacht.Bootstrap: Dies ist ein Frontend-Framework, das Gestaltungsvorlagen für die Webentwicklung enthält.
Daneben kann das HTML-Dokument auch Kommentare enthalten. Hier ist das nicht der Fall, aber damit du einen Kommentar erkennst, ist hier ein Beispiel:
<!--Dies ist ein Kommentar-->Das Untersuchen des HTML-Dokuments schließen wir damit ab. Du hast festgestellt, dass die Webseite externe Ressourcen einbindet. Das wird in der Enumeration noch eine Rolle spielen.
Untersuchen von JavaScript
Der Debugger ermöglicht Entwicklern, den JavaScript-Code einer Webseite zu untersuchen. Der Debugger besteht aus drei Fenstern:

Links werden unter Sources alle JavaScript-Dateien angezeigt, die eine Webseite lädt.
Durch Anklicken einer JavaScript-Datei wird sie im mittleren Fenster Outline Pane geöffnet.
Der Quellcode lässt sich so untersuchen.
Das untere Fenster Breakpoint Pane dient dem Debuggen, also dem Prozess, Fehler und unerwartetes Verhalten zu identifizieren und zu beheben.
Die Fenster Outline Pane und Breakpoint Pane können durch einen Klick auf die im Screenshot rot gekennzeichneten Icons aus- bzw. eingeblendet werden.
Untersuchen von Stylesheets
Zum Quellcode gehören auch Stylesheets. Diese sind aber weniger von Schwachstellen betroffen als HTML oder JavaScript. Deshalb verzichten wir hier darauf, die Stylesheets zu untersuchen.
Falls du sie dir dennoch ansehen möchtest, dann musst du den Tab Style Editor in den Entwicklungstools öffnen.
Darin werden die Cascading Style Sheets (CSS) aufgeführt, mit denen das Layout der Webseite gesteuert wird:

Die CSS-Regeln können hier temporär bearbeitet werden.
Untersuchen von HTTP-Headern
Neben dem Quellcode ist die Kommunikation zwischen deinem Browser und dem Webserver noch eine mögliche Quelle, um Informationen über die Webapplikation zu gewinnen. Mit der Netzwerkanalyse lässt sich der Datenverkehr zwischen dem Webbrowser und dem Webserver untersuchen. Wird sie geöffnet, dann erscheint standardmäßig eine Liste aller Anfragen:

Die Anfragen können gefiltert werden.
Wählt man zum Beispiel statt All die Option HTML aus, werden nur Anfragen angezeigt, die HTML-Dateien anfordern.
Die wichtigsten Spalten in der Tabelle sind:
Status: Enthält den HTTP-Statuscode, den der Webserver für eine Anfrage an den Client zurückgibtMethod: Gibt die HTTP-Methode an, über die der Client mit dem Webserver kommuniziert, um Ressourcen anzufordern oder zu ändernDomain: Gibt den Hostnamen des Webservers an, von dem eine Ressource angefordert wirdFile: Enthält den Namen der Ressource, die der Webbrowser anfordert
Wählt man eine Anfrage in der Liste aus, öffnen sich die Anfragedetails.
Unter dem Tab Headers sind die HTTP-Header enthalten, die der Browser und der Webserver austauschen:
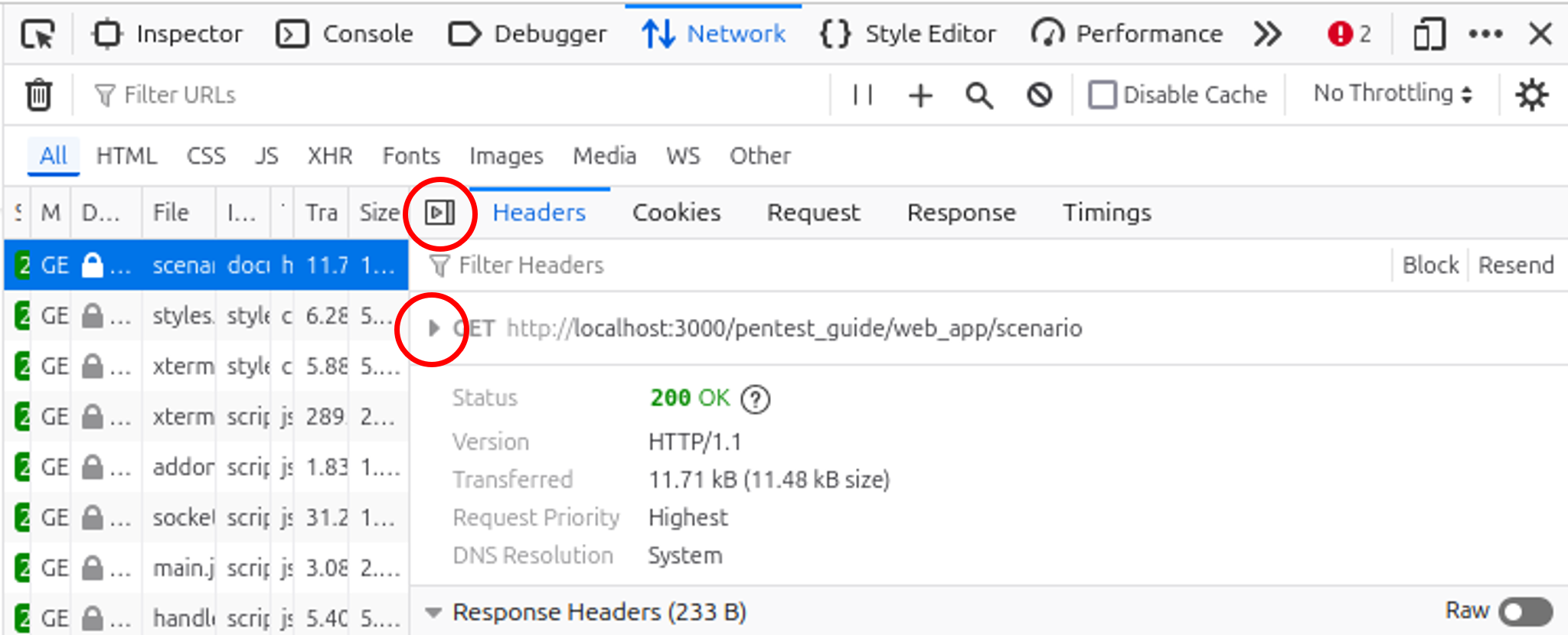
Die Anfragedetails lassen sich durch einen Klick auf das obere rot umrandete Icon schließen. Weitere Details zur Anfrage lassen sich anzeigen, wenn das untere rot umrandete Dreieck angeklickt wird.
Aus Antwort- und Anfrage-Header geht also hervor:
- Der Webserver verwendet Nginx in der Version 1.24.0 auf einem Ubuntu-Betriebssystem.
- Beim Senden der Anfrage wird ein Cookie namens
sessionmitgeschickt.
Webseiten nutzen Cookies, um Daten clientseitig zu speichern.
Diese werden im Web-Speicher abgelegt. Der Tab Storage lässt sich öffnen, wenn man sich weitere Tabs anzeigen lässt:

Im Web-Speicher muss man unter Cookies einen Host wählen. Dann wird eine Tabelle aller Cookies des Hosts angezeigt:
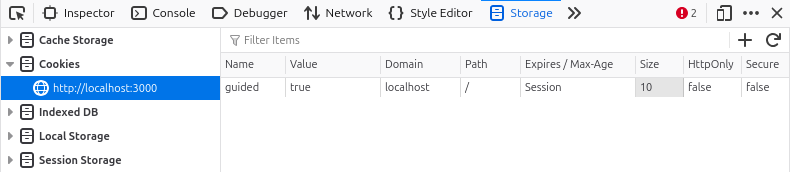
Die wichtigsten Informationen zu den Cookies sind:
Name: Enthält den Namen des CookiesValue: Enthält den Inhalt des CookiesExpires / Max-Age: Gibt die Gültigkeitsdauer des Cookies anHttpOnly: Gibt an, ob der Cookie nur über HTTP-Anfragen und nicht über JavaScript zugänglich istSecure: Gibt an, dass der Cookie nur über sichere HTTPS-Verbindungen übertragen werden darf
Bei dem Cookie session handelt es sich offensichtlich um einen Session-Cookie, das eingesetzt wird, damit der Benutzer während des Besuchs auf der Webseite angemeldet bleibt und wiedererkannt wird.
Nähere Informationen zu Sessions und Cookies findest du hier.
Directory-Bruteforcing
Bisher hat du die Informationen untersucht, die ein Webserver einem normalen Benutzer einer Webapplikation zur Verfügung stellt. Daneben kann er weitere Ressourcen wie zum Beispiel einen Admin-Bereich haben, auf die er einen normalen Nutzer jedoch nicht hinweist. Um diese zu finden, gibt es Software-Tools wie gobuster.
Sie suchen aktiv nach Verzeichnissen und Dateien und helfen dadurch unauffällige Inhalte aufzudecken. Dafür werden HTTP-Anfragen an einen Server gesendet, wobei die URL mithilfe von Wortlisten generiert wird, die für Webapplikationen typische Verzeichnis- und Dateinamen enthalten. Aus dem Statuscode in der HTTP-Antwort des Servers leiten die Programme ab, ob die URL existiert oder nicht.
Mit folgendem Befehl führst du gobuster aus und lässt es nach weiteren Dateien und Verzeichnissen des Webservers suchen:
gobuster dir -u <Ziel-URL> -w <Pfad/zur/Wortliste>Die Option -u gibt dabei die Ziel-URL an, die gescannt werden soll, während -w den Pfad zur Wortliste definiert.
Diese enthält Namen von Verzeichnissen oder Dateien, nach denen gesucht wird.
Für die Übung haben wir eine kurze Wortliste auf dem Webserver abgelegt, die durch das Kürzen dieser Liste entstanden ist.
gobuster findet also vier weitere Ressourcen.
Werden diese angefordert, gibt der Webserver den HTTP-Statuscode 302 zurück.
Da du nicht eingeloggt bist, hast du die keinen Zugriff auf diese vier Ressourcen. Forderst du sie an, wirst du zur Login-Seite umgeleitet. Darum gibt der Webserver den HTTP-Statuscode 302 Found zurück.
Falls du dich wunderst, warum die URL der Login-Seite jetzt den Query-Parameter next enthält: Dieser Parameter sorgt dafür, dass der Benutzer nach dem Einloggen zur ursprünglich angeforderten Webseite weitergeleitet wird.
Damit soll vorerst für die Reconnaissance reichen. Du hast nun einen ersten Überblick über die Webapplikation gewonnen und kennst
- Die Interaktionsmöglichkeiten auf der Seite
/login - Die Bibliotheken und Frameworks, die die Webseite verwendet
- Details zum Webserver
- Weitere Seiten, auf die du aber ohne Authentifizierung nicht zugreifen kannst
Im nächsten der Schritt, der Enumeration, wirst du gezielt nach Schwachstellen auf der Seite /login suchen, um zunächst Zugriff auf die weiteren Ressourcen zu bekommen.