
Einleitung
Hier findest du theoretische Grundlagen zu Webapplikationen, die dir später beim Untersuchen auf Schwachstellen helfen können.
Das Client-Server-Modell
Das Client-Server-Modell ist die Grundlage vieler Webapplikationen.
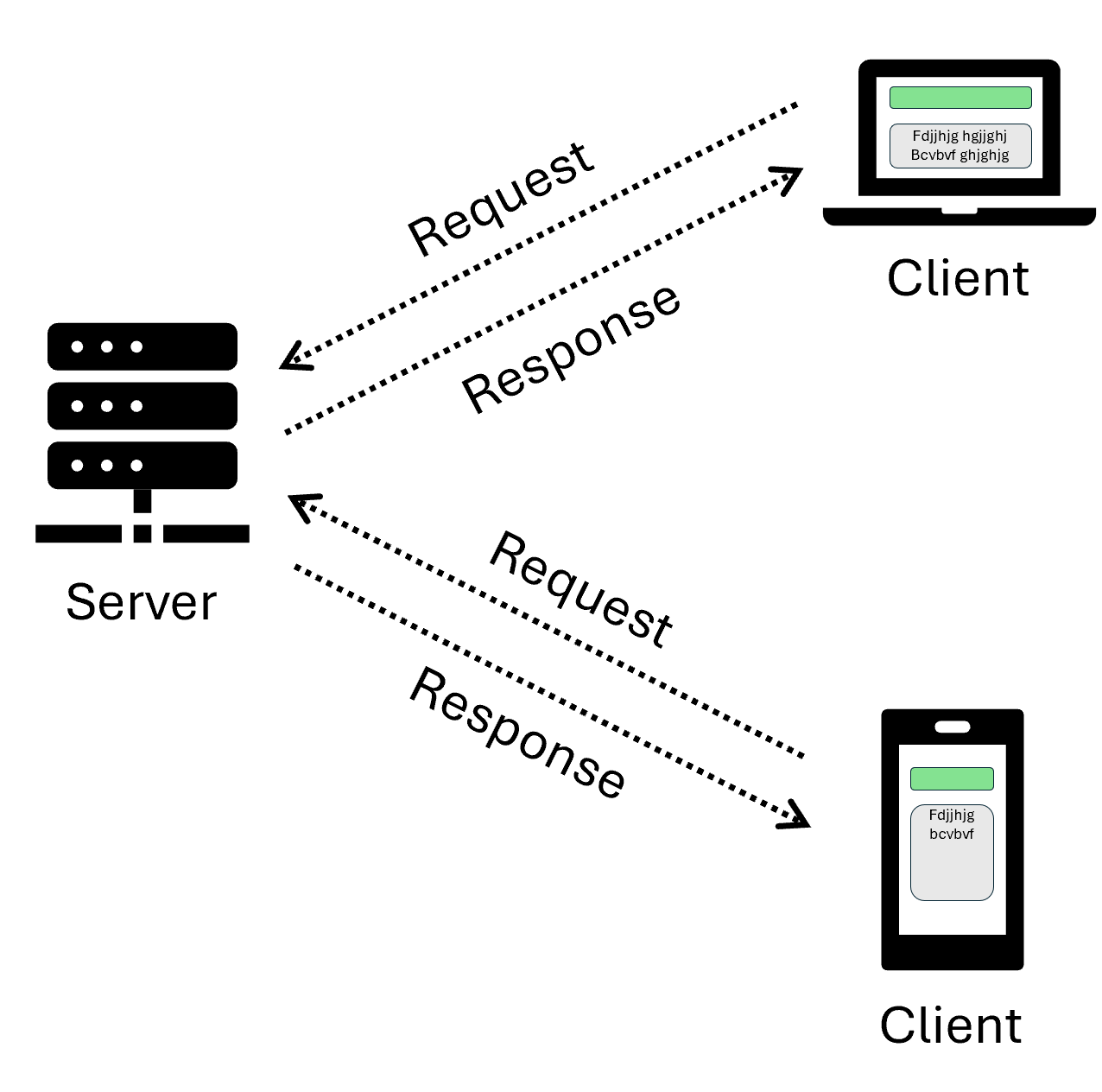
Ein Client ist ein Gerät oder eine Software, die Anfragen an einen Server stellt.
Clients sind typischerweise Endbenutzergeräte wie Computer, Smartphones oder Softwareanwendungen, die Daten oder Dienste benötigen. Sie initiieren die Interaktion mit dem Server.
Ein Server ist ein Gerät oder eine Software, die Dienste, Daten oder Ressourcen bereitstellt.
Server laufen häufig auf leistungsfähigen Computern oder in der Cloud und empfangen, verarbeiten und beantworten die Anfragen von Clients. Ein Webserver liefert beispielsweise Webapplikationen und Webseiten aus, die über einen Webbrowser als Client angefordert werden und dem Benutzer angezeigt werden.
Server- und clientseitig werden verschiedene Webtechnologien eingesetzt.
Client-Side-Technologien werden im Browser des Benutzers ausgeführt und sind verantwortlich für die Benutzeroberfläche und die Interaktivität der Webanwendung. Die wichtigsten Client-Side-Technologien sind:
- HTML (HyperText Markup Language) zur Strukturierung des Inhalts von Webseiten
- CSS (Cascading Style Sheets) zur Gestaltung von Webseiten
- JavaScript als Programmiersprache zur Implementierung von interaktiven und dynamischen Funktionen
Server-Side-Technologien werden auf dem Server ausgeführt und sind verantwortlich für die Verarbeitung von Daten, Geschäftslogik und das Bereitstellen von Inhalten an den Client. Die wichtigsten Server-Side-Technologien sind:
- Webserver: Der Webserver ist eine Software (z. B. Apache HTTP Server), die statische Inhalte ausliefert und Anfragen emfängt und verarbeitet.
- Server-Side-Programmiersprachen: Sie verarbeiten in der Regel die Anfragen und generieren dynamische Inhalte.
- Datenbanken: Sie speichern und verwalten die Anwendungsdaten und ermöglichen effiziente Abfragen und Manipulationen
Webtechnologien
HTML
HTML ist die Standardsprache, um Webseiten zu erstellen. Es handelt sich dabei um eine Auszeichnungssprache, die es ermöglicht, Inhalte wie Text, Bilder oder Videos auf Webseiten zu strukturieren und darzustellen.
HTML verwendet Tags (Elemente), um den Inhalt zu strukturieren und zu formatieren.
Diese Tags sind in spitze Klammern eingeschlossen, z. B. <tagname>Inhalt</tagname>.
Die meisten Elemente bestehen aus einem öffnenden und einem schließenden Tag.
Ein einfaches HTML-Dokument ist hier dargestellt:
Der Webbrowser stellt das HTML-Dokument so dar:
Ein HTML-Dokument besteht aus einem hierarchischen Baum von Elementen. Es benötigt bestimmte grundlegende Tags, um korrekt strukturiert und gültig zu sein. Diese sind:
| Tag | Beschreibung |
|---|---|
<!DOCTYPE html> |
Deklaration des Dokumenttyps |
<html> |
Wurzelelement des HTML-Dokuments |
<head> |
Enthält Metadaten über das Dokument, wie den Titel, Verknüpfungen zu weiteren Dateien |
<body> |
Enthält den gesamten sichtbaren Inhalt der Webseite, wie Texte, Bilder, Links, Formulare usw. |
Innerhalb des <body>-Elements, das den sichtbaren Inhalt der Webseite enthält, werden verschiedene HTML-Elemente eingesetzt.
Dies sind beispielsweise:
| Tag | Beschreibung |
|---|---|
<h1> bis <h6> |
Überschrift der Ebene 1 bis 6 (englisch: Heading) |
<p> |
Absatz (englisch: Paragraph) |
<ul> |
Ungeordnete Liste (englisch: Unordered list) |
<ol> |
Geordnete Liste (englisch: Ordered list) |
<li> |
Listenelement (englisch: List element) |
<a> |
Hyperlink (englisch: Anchor) |
<img> |
Bild (englisch: Image) |
HTML-Tags können Attribute haben, die zusätzliche Informationen bereitstellen:
- Bei dem Hyperlink
<a href="https://www.example.com" title="Visit">External Link</a>gibt es z. B. die Attributehref: Gibt das Ziel des Links antitle: Fügt einem Element einen Tooltip hinzu, der beim Überfahren mit der Maus angezeigt wird
- Bei dem Bild
<img src="/images/images.png" alt="A duck">gibt es z. B. die Attributesrc: Gibt den Pfad zum Bild analt: Gibt einen Alternativtext für das Bild an
Beim Aufruf einer Webseite und damit eines HTML-Dokuments interpretiert der Webbrowser den HTML-Code und stellt die Webseite entsprechend den im HTML definierten Anweisungen dar. Dies wird als Rendering bezeichnet.
Rendering ist der Prozess, bei dem ein Webbrowser HTML-Code interpretiert und daraus die visuelle Darstellung einer Webseite erzeugt. Dies beinhaltet die Anordnung und Gestaltung von Text, Bildern und anderen Elementen entsprechend den im HTML und CSS definierten Anweisungen.
CSS
HTML liefert eine grundlegende funktionsfähige Struktur für Webseiten. Die Elemente werden entsprechend den Voreinstellungen des Browsers dargestellt. Damit ist z. B. ein weißer Hintergrund, die Schriftgröße und -art von Textelementen und die Schriftfarbe festgelegt. Um das Erscheinungsbild und Layout einer Webseite umfassend zu gestalten, werden Cascading Style Sheets (CSS) eingesetzt.
CSS wird in der Regel in einer separaten .css-Datei gespeichert und im <head>-Bereich in das HTML-Dokument eingebunden:
h1 {
background-color: gray;
color: white;
font-family: cursive;
}
Das geschieht mit dem <link>-Tag:
<head>
<link rel="stylesheet" href="styles.css">
</head>Das Tag enthält zwei Attribute:
rel="stylesheet": Gibt an, dass es sich bei dem verlinkten Dokument um ein Stylesheet handelthref="styles.css": Gibt den Pfad zum Stylesheet an
CSS-Anweisungen bestehen aus
- Selektoren, die bestimmen, welche HTML-Elemente gestylt werden
- Eigenschaften und Werte, die bestimmen, wie die ausgewählten Elemente gestylt werden
Die Abbildung zeigt eine CSS-Anweisung:

Der Selektor ist dabei der Elementtyp.
In diesem Fall werden also h1-Elemente gestylt, wobei der Hintergrund, die Schriftfarbe und die Schriftfamilie angepasst werden.
Es sind auch andere Selektoren möglich.
So lassen sich Elemente über das class-Attribut einer Klasse zuordnen, sodass diese über den Klassenselektor ansprechbar sind:

Das HTML in der Abbildung enthält eine zweite Überschrift "Heading 2", die zur Klasse "black" gehört.
Über den Klassenselektor .black wird diese zweite Überschrift im CSS angesprochen und eine schwarze Schriftfarbe festgelegt.
JavaScript
Das Document Object Model (DOM)
Um Webseiten dynamisch und interaktiv zu machen, wird die Programmiersprache JavaScript eingesetzt. Es wird auf der Client-Seite im Browser ausgeführt und ermöglicht die Manipulation von HTML und CSS, um Inhalte dynamisch zu ändern, und Nutzerinteraktionen. Dafür nutzt JavaScript das Document Object Model (DOM).
Das Document Object Model (DOM) ist eine Programmierschnittstelle (API) für HTML-Dokumente. Es stellt das HTML-Dokument als eine hierarchische Baumstruktur dar, bei der jeder Knoten ein Teil des Dokuments ist.
In der Abbildung links ist das DOM und rechts ist das entsprechende HTML-Dokument dargestellt:

Jedes Element wie <head>, <h1> und <li> wird zu einem Knoten im Baum.
Mit JavaScript können Elemente im DOM ausgewählt werden z. B. durch
let elements = document.getElementsByClassName('black');
Dabei werden alle Elemente gesucht, die zur Klasse black gehören und als sogenannte HTMLCollection in der Variable elements gespeichert.
Die HTMLCollection ist einem Array ähnlich, sodass über Indexwerte auf Elemente zugegriffen werden kann.
Mit JavaScript können dann CSS-Eigenschaften oder der HTML-Inhalt eines Elements geändert werden:
Der Webbrowser stellt das HTML-Dokument so dar:
Wie in dem Beispiel zu sehen, kann JavaScript über das <script>-Element direkt in ein HTML-Dokument eingebunden werden.
Alternativ ist es auch möglich, ganze JavaScript-Dateien über das <script>-Element mit dem src-Attribut zu laden:
<head>
<script src="/path/to/script" type="text/javascript"></script>
</head>Events
Ein Event (Ereignis) ist ein Signal, das angibt, wenn im Dokument oder auf einer Webseite etwas passiert ist. Es tritt auf, wenn Benutzer mit der Webseite interagieren (z. B. durch Klicken, Scrollen, Eingaben über die Tastatur) oder wenn sich der Zustand des Dokuments ändert (z. B. das Laden einer Seite oder das Beenden einer Animation).
Es werden verschiedene Event-Typen unterschieden:
| Event-Typ | Beispielhafte Schlüsselworte |
|---|---|
| Mausereignisse | click, mousedown, mouseup, mouseover |
| Tastaturereignisse | keydown, keypress, keyup |
| Formularereignisse | submit, change, focus |
| Dokument-/Fensterereignisse | load, unload, scroll, DOMContentLoaded |
Ereignisse werden häufig verwendet, um Interaktivität in Webseiten zu ermöglichen.
Dafür gibt es sogenannte Event-Listener.
Ein Event-Listener ist eine Funktion, die auf ein bestimmtes Ereignis wartet.
Wenn das Ereignis eintritt, wird der Event-Listener ausgeführt.
Event-Listener werden in JavaScript mithilfe der Methode addEventListener() hinzugefügt.
In dem folgenden Beispiel sind zwei Event-Listener enthalten, die dafür sorgen, dass sich der Text der Überschrift ändert, wenn die Maus über die Überschrift bewegt wird. Verlässt die Maus die Überschrift, erscheint wieder die ursprüngliche Überschrift.
Der Webbrowser stellt das HTML-Dokument so dar:
HTTP/HTTPS
Was ist HTTP/HTTPS?
Webbrowser und Webserver kommunizieren über das Hypertext Transfer Protocol (HTTP). Es basiert auf dem Client-Server-Modell und wird hauptsächlich verwendet, um Ressourcen wie HTML-Dokumente von einem Webserver zu einem Webbrowser zu übertragen.
Es hat folgende Eigenschaften:
- HTTP ist ein Protokoll der Anwendungsschicht, das auf TCP aufbaut.
- Es ist ein zustandsloses Protokoll. Jede Anfrage und Antwort ist unabhängig voneinander.
HTTPS ist eine Erweiterung von HTTP, die eine verschlüsselte Kommunikation über TLS/SSL ermöglicht, um die Vertraulichkeit und Integrität der Daten zu gewährleisten.
Die Abbildung zeigt, wie die Kommunikation zwischen Client und Server abläuft:

Der Client initiiert die Kommunikation mit dem Server über eine HTTP-Anfrage, auch HTTP Request genannt. Diese Anfrage gibt an, welche Ressource der Webbrowser anfordert. Das kann zum Beispiel eine bestimmte Webseite, ein Bild oder ein Video sein.
Nachdem der Webserver die Anfrage erhalten hat, beginnt er damit, die angeforderten Daten zu sammeln und zu verpacken. Ist dies abgeschlossen, sendet er die Daten in Form einer HTTP-Antwort oder auch HTTP Response zurück. Die Daten werden dann im Webbrowser dargestellt.
HTTP-Nachrichten
HTTP-Nachrichten bestehen aus:
- Kontrolldaten (Control Data), die die Nachricht beschreiben
- Nachrichtenköpfen (Headers), die aus Name-Wert-Paaren bestehen und zusätzliche Informationen über den Absender, den Inhalt oder den Kontext liefern.
- Inhalt (Content)
Hier ist ein Beispiel für eine HTTP-Anfrage:
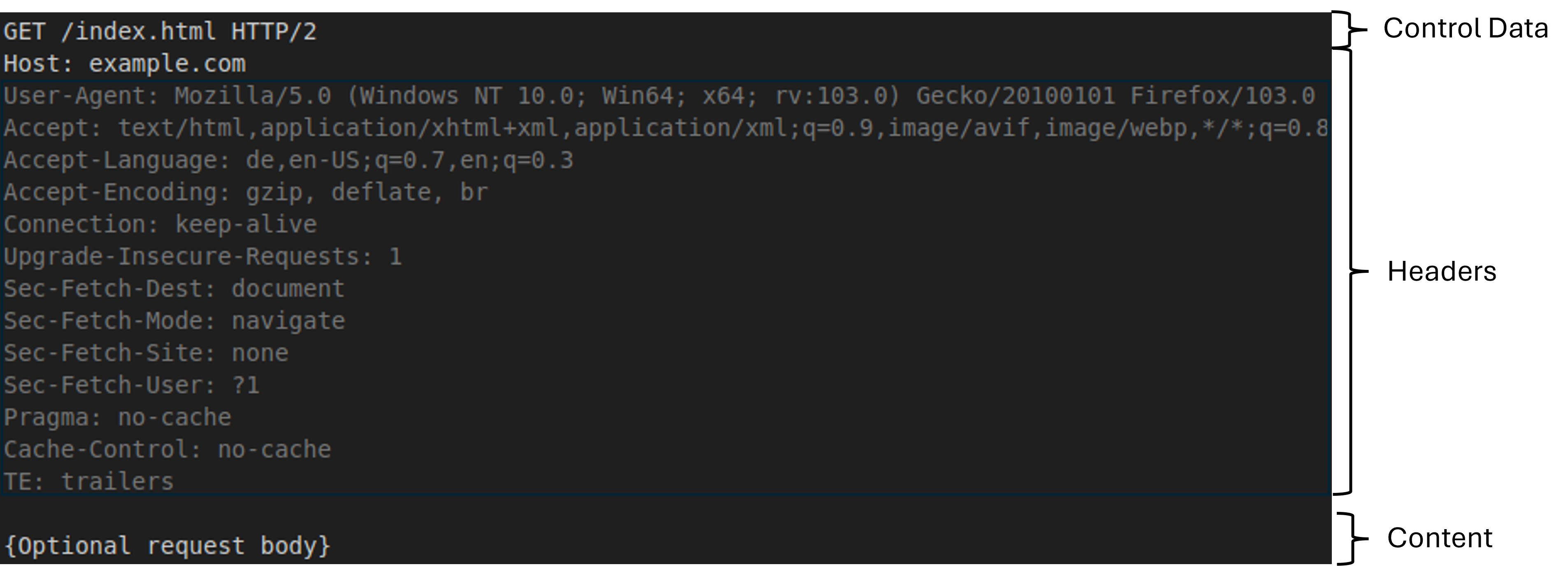
Mit dieser Anfrage wird die Ressource /index.html des Hosts example.com angefordert.
Sie besteht aus:
- Kontrolldaten (Control Data), die eine Anfrage-Methode, ein Anfrage-Ziel und eine Protokollversion enthalten
- Headern, wobei einzig der Header Host erforderlich ist, da er den Ziel-Host der Anfrage spezifiziert
Die ausgegrauten Header sind dagegen optional. - Optionalen Inhalt (Content)
Hier werden Daten z. B. eines Formulars an den Webserver übertragen. Wenn, wie in der Abbildung nur Ressourcen angefordert werden, ist er in der Regel leer.
In HTTP-Anfragen gibt es mehrere Methoden, die für die Kommunikation zwischen einem Client und einem Server verwendet werden. Jede Methode hat einen spezifischen Zweck und wird in verschiedenen Kontexten verwendet. Die gängigsten HTTP-Methoden sind:
| Methode | Beschreibung |
|---|---|
| GET | Abrufen von Ressourcen |
| POST | Senden von Daten |
| PUT | Aktualisieren von Daten |
| DELETE | Löschen einer Ressource |
Angefordert werden Ressourcen über URL (Uniform Resource Locator). Eine URL ist eine Webadresse, die den Ort einer Ressource im Internet angibt und den Zugriff darauf ermöglicht:
protocol://hostname[:port][/path]/file[?param=value]Hier ist der Aufbau einer typischen URL erklärt:
| Bestandteil | Erklärung |
|---|---|
| Protocol | Protokoll, das zur Kommunikation verwendet wird (Zum Aufrufen von Webseiten werden HTTP oder HTTPS verwendet.) |
| Hostname | Domain oder IP-Adresse des Servers, der die Ressource bereitstellt |
| Port (optional) | Portnummer, über die die Verbindung hergestellt wird (Standardmäßig verwendet HTTP Port 80 und HTTPS Port 443. Der Port wird üblicherweise nur angegeben, wenn er vom Standardport abweicht.) |
| Path (optional) | Pfad zur spezifischen Ressource auf dem Webserver |
| File | Name der abgerufenen Ressource (z. B. eine Datei) |
| Parameter (optional) | Übergabe von zusätzlichen Daten zur Anfrage |
Auf die HTTP-Anfrage antwortet der Webserver mit:
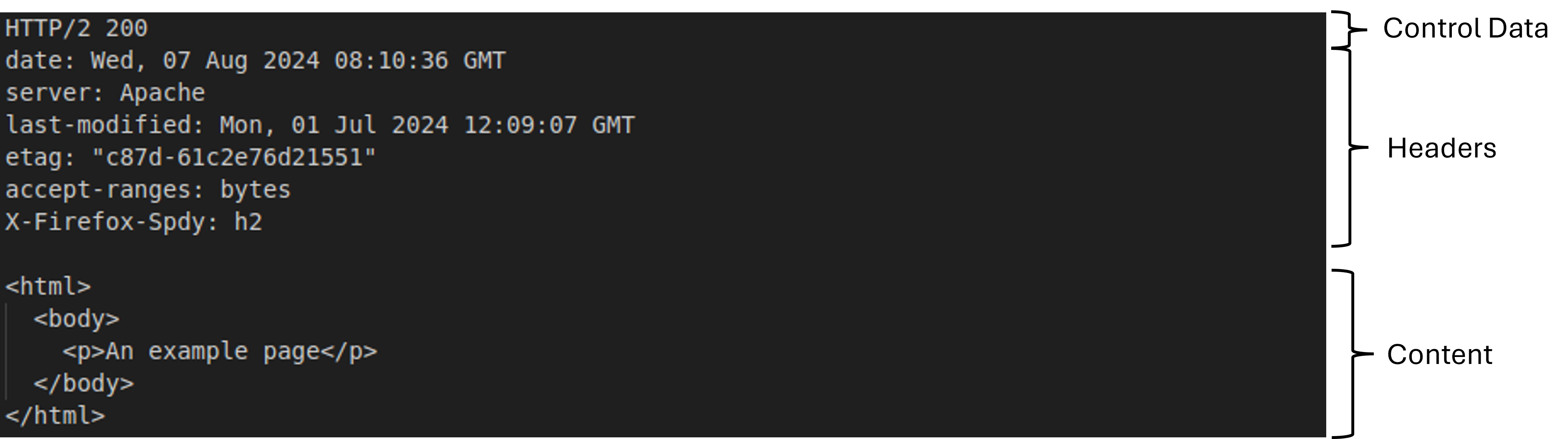
Diese HTTP-Antwort besteht aus:
- Kontrolldaten (Control Data), die eine Protokollversion und einen Statuscode enthalten
- Headern mit wichtigen Informationen, die vom Webbrowser verwendet werden, um die Antwort richtig zu verarbeiten
- Inhalt (Content), der die eigentlichen Daten enthält, die vom Server an den Client gesendet werden
Dies kann eine Vielzahl von Inhalten umfassen, je nach dem Typ der Anfrage und der Art der Ressource. Wenn, wie in dem Beispiel ein HTML-Dokument angefordert wurde, enthält er HTML-Code, der vom Webbrowser gerendert wird.
Die erste Zeile der HTTP Response enthält einen Statuscode, der den Status einer HTTP-Anfrage angibt. Die wichtigsten Statuscodes sind:
| Code | Name | Bedeutung |
|---|---|---|
| 100 | Continue | Dies ist eine vorläufige Antwort. Die Anfrage wird weiter bearbeitet. |
| 200 | Ok | Die Anfrage war erfolgreich und die angeforderte Ressource wird im Body der Antwort zurückgegeben. |
| 201 | Created | Anfrage war erfolgreich und eine neue Ressource wurde erstellt |
| 301 | Moved Permanently | Die angeforderte Ressource wurde dauerhaft an eine neue URL verschoben. |
| 304 | Not Modified | Die Ressource wurde seit der letzten Anforderung nicht geändert und die gecachte Version kann verwendet werden. |
| 400 | Bad Request | Die Anfrage des Clients war fehlerhaft oder unvollständig. |
| 403 | Forbidden | Der Client hat keine Zugriffsrechte auf die Ressource. |
| 404 | Not Found | Die angeforderte Ressource konnte auf dem Server nicht gefunden werden. |
| 500 | Internal Server Error | Der Server hat einen unerwarteten Fehler festgestellt, der ihn daran hindert, die Anfrage zu erfüllen. |
In den nächsten Zeilen folgen Header. Am häufigsten verwendet werden:
| Header | Bedeutung |
|---|---|
| content-type | Gibt den Medientyp des Inhalts an, der im Body der Antwort enthalten ist (Für HTML-Dokumente ist dies z. B. text/html.) |
| Date | Gibt das Datum und die Uhrzeit an, zu der die Antwort gesendet wurde |
| Server | Gibt Informationen über den Server an, der die Antwort gesendet hat, einschließlich des Server-Softwares |
| ETag | Ein Identifikator, der die Version der Ressource bezeichnet. Er wird verwendet, um die Konsistenz von Cache-Anfragen zu überprüfen |
States und Sessions
Bei HTTP (Hypertext Transfer Protocol) handelt es sich um ein zustandsloses Protokoll, sodass jeder Request und jede Response unabhängig voneinander verarbeitet wird. Der Webserver speichert also keine Informationen darüber, wer die Anfrage gestellt hat oder was vorherige Anfragen waren. Diese Eigenschaft führt zu einem Problem: Wie kann der Server Benutzerinformationen oder den Zustand einer Sitzung beibehalten?
Hier kommen States und Sessions ins Spiel. Sie sind erforderlich, um den Mangel an Zustandsinformationen in HTTP auszugleichen und ermöglichen es, eine kontinuierliche Interaktion zwischen Benutzer und Server über mehrere Anfragen hinweg aufrechtzuerhalten.
Eine Session ist eine serverseitige Methode, um den Zustand (state) eines Benutzers über verschiedene HTTP-Anfragen hinweg zu speichern. Dies wird in der Regel durch die Zuordnung eines eindeutigen Session-Tokens realisiert, der zwischen Client und Server ausgetauscht wird.
Zur Realisierung von Sessions werden folgende Schritte ausgeführt:

- Wenn ein Client zum ersten Mal eine Anfrage an den Server sendet (z. B. beim Login), erstellt der Server eine eindeutige Session-ID. Diese wird als Identifikator für die Sitzung des Benutzers verwendet.
- Die Benutzerdaten werden zusammen mit der Session-ID auf dem Server gespeichert.
- Der Server sendet die Session-ID in seiner Antwort an den Client.
- Die Session-ID wird im Browser des Clients gespeichert, häufig in Form eines Cookies.
- Bei jeder weiteren Anfrage des Clients wird die Session-ID vom Browser an den Webserver gesendet. Der Server verwendet diese ID, um die gespeicherten Sitzungsdaten des Browsers zu akualisieren oder abzurufen.
Ein Cookie ist eine kleine Datei, die vom Webserver an den Browser gesendet und dort gespeichert wird, um benutzerspezifische Daten über mehrere Anfragen hinweg zu speichern und wieder zu senden.
Damit ein Cookie auf der Client-Seite (im Browser) gespeichert wird, muss der Server eine spezielle Anweisung im HTTP-Response-Header an den Client senden. Diese Anweisung erfolgt über den Set-Cookie-Header.

Der Browser interpretiert diesen Header und speichert den Cookie mit den angegebenen Attributen. Bei nachfolgenden HTTP-Anfragen an dieselbe Domain fügt der Browser den Cookie automatisch in die Anfrage ein, indem er einen Cookie-Header hinzufügt:
GET /home HTTP/1.1
Host: www.example.com
Cookie: sessionId=abc123
Dies geschieht nur, wenn die Anfrage bestimmte Bedingungen des Cookies erfüllt. Dies sind beispielsweise:
- Die Anfrage muss zur im Cookie angegebenen
Domaingehören. - Die angeforderte URL muss mit dem im Cookie definierten
Pathübereinstimmen oder darunter liegen. - Falls die Flag
Securegesetzt ist, wird der Cookie nur über HTTPS-, nicht jedoch über HTTP-Verbindungen gesendet. - Die Anfrage muss erfolgen, bevor der unter
Expiresangegebene Zeitpunkt erreicht ist.
Datenaustausch
Client und Server tauschen Daten oft in standardisierten Formaten aus, um die Interoperabilität zwischen verschiedenen Systemen und Plattformen zu gewährleisten. Zwei der am häufigsten genutzten Formate sind XML (Extensible Markup Language) und JSON (JavaScript Object Notation).
Beide Formate sind menschenlesbar und hierarchisch strukturiert. Die Abbildung zeigt eine Liste bestehend aus zwei Benutzern im XML- und im JSON-Format:
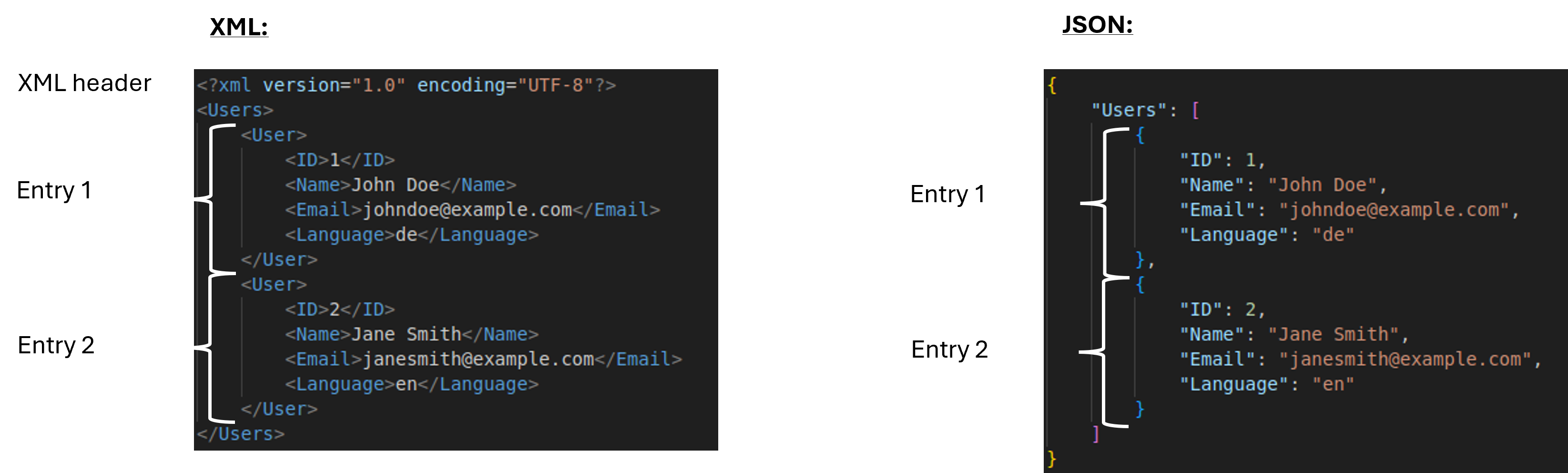
XML verwendet Tags (<Tag></Tag>) zur Strukturierung der Daten und kann komplexere Schemata unterstützen.
Der XML-Header gibt die XML-Version und die Zeichenkodierung an.
JSON verwendet Schlüssel-Wert-Paare, die durch geschweifte Klammern {} gekennzeichnet sind und durch Doppelpunkte : getrennt werden.
JSON ist als leichtgewichtige Alternative speziell für Webanwendungen populär, da es nativ in JavaScript eingebunden ist.
Datenbanken
Datenbanken sind ein zentraler Bestandteil von Webapplikationen, wenn für ihre Ausführung Daten gespeichert und verwaltet werden müssen. Über eine Schnittstelle kommuniziert die Webanwendung mit der Datenbank, um Anfragen wie das Speichern neuer Daten oder das Abrufen vorhandener Datensätze zu verarbeiten.
Ein Datenbankmanagementsystem (DBMS) ist eine Software, die die Erstellung, Verwaltung und Interaktion mit Datenbanken ermöglicht. DBMS bieten eine strukturierte Umgebung, in der Daten organisiert, gespeichert und abgerufen werden können, und stellen sicher, dass diese Prozesse effizient, sicher und konsistent ablaufen.
Werden Daten in Tabellen mit vordefinierten Schemata organisiert und Beziehungen zwischen den Tabellen über Schlüssel definiert, dann liegt eine relationale Datenbank vor.
Die Abbildung zeigt drei Tabellen der Datenbank MyShop.

Die Tabelle products speichert Informationen zu den Produkten, wobei jedes Produkt durch eine eindeutige id identifiziert wird.
In der Tabelle customers werden Kundendaten hinterlegt, wobei jeder Kunde ebenfalls eine eindeutige id erhält.
Die Tabelle orders stellt die Verbindung zwischen Kunden und ihren Bestellungen her.
Jede Bestellung wird durch eine eigene id eindeutig gekennzeichnet.
Die customer_id verweist auf den Kunden, der die Bestellung aufgegeben hat, und die product_id auf das erworbene Produkt.
Die Verwaltung der Daten geschieht mithilfe einer Datenbanksprache wie SQL, die für relationale Datenbanken eingesetzt wird.
Structured Query Language (SQL) ist die standardisierte Sprache zur Interaktion mit relationalen Datenbanken. SQL ermöglicht es Benutzern, Daten abzurufen, zu manipulieren und zu verwalten.
Zu den grundlegenden SQL-Befehlen gehören:
| SQL-Befehl | Bedeutung |
|---|---|
SELECT |
Abfragen von Daten |
INSERT |
Einfügen neuer Daten |
UPDATE |
Aktualisieren bestehender Daten |
DELETE |
Löschen von Daten |
Hier ist eine SQL-Abfrage, die die gesamte Tabelle customer ausgibt:

Das Schlüsselwort SELECT dient dazu, Daten aus der Datenbank auszuwählen
Das Sternchen * ist ein Platzhalter, so dass alle Spalten ausgegeben werden.
Nach dem Schlüsselwort FROM folgt der Name der Tabelle, aus der die Daten abgerufen werden.
Es werden also alle Datensätze mit sämtlichen Attributen aus der Tabelle customers abgefragt.
Der SQL-Befehl wird mit einem Semikolon ; abgeschlossen.
Da Tabellen in der Praxis meist umfangreicher und weniger übersichtlich sind als in unserem Beispiel, ist es oft sinnvoll, nur bestimmte Attribute der Datensätze anzuzeigen.
In solchen Fällen gibt man die gewünschten Spalten explizit an.
Hier ist zum Beispiel eine SQL-Abfrage, die nur die Passwörter aus der Tabelle customers ausgibt.
Dafür wird der Spaltenname password direkt nach dem Schlüsselwort SELECT angegeben.

Die Datensätze können mithilfe des Schlüsselworts WHERE gefiltert werden.
In der folgenden SELECT-Anweisung wird zum Beispiel nach der id gefiltert, sodass nur der Datensatz mit der ID 01 ausgegeben wird.

Mit dem Schlüsselwort UNION werden die Ergebnisse von zwei oder mehr SELECT-Abfragen kombiniert und als eine einzige Ergebnismenge zurückgegeben.
So werden mit der folgenden Abfrage die Spalte name aus der Tabelle products und die Spalte name aus der Tabelle customers gemeinsam ausgegeben.

Bei der Verwendung von UNION ist Folgendes zu beachten:
- Beide
SELECT-Abfragen müssen die gleiche Anzahl an Spalten haben. - Die Spalten in den jeweiligen Positionen der
SELECT-Anweisungen müssen kompatible Datentypen besitzen.